3.3장까진 Transport Layer가 무엇을 위해 존재하고, 기본적으로 어떤 기능을 수행하는지 살펴봤다. 이 과정에서 mux/demux에 대해 살펴봤었고, 또한 checksum 기능을 살펴봄으로써, UDP가 제공하는 모든 기능(mux/demux & checksum)들과 UDP의 segment 구조까지 살펴보았다. 그럼 이제 전송 계층에서 구현된 또 다른 프로토콜인 TCP 를 살펴봄으로써 TCP를 통해 또 어떠한 서비스들을 제공받을 수 있는지 살펴볼 차례이다.
Transport Layer에서 제공할 수 있는 "신뢰성"에 대해 알기 위해 3.4장을 살펴볼 것이다. 3.4장에서는 "신뢰성 있는 데이터 전송"의 원리를 실제 적용 방식에 점점 다가가는 식으로 단계단계 나아갈 것이다. 이후 3.5장에선 "신뢰성 있는 데이터 전송"이 실제로 구현되어 있는 TCP 프로토콜을 살펴본 후, 3.6장과 3.7장에선 이 TCP가 제공해주는 또 한가지의 기능, "Congestion Control"에 대해 면밀히 살펴볼 것이다.
자, 이제 "신뢰성 있는 데이터 전송"에 대해 살펴볼까.
Reliable Data Transfer (RDT)
RDT - 개요
줄여서 RDT 라는 프로토콜을 만들어가는 과정을 살펴볼 것이다.

RDT : 추상적인 서비스와 그 서비스의 구현
| (a) 서비스 | (b) 서비스의 구현 |
|---|---|
transport layer에서 reliable channel을 통해 데이터를 전달하는 서비스를 제공하고자 한다. |
이 서비스의 구현을 위해서는, 실제 네트워크가 가지는 unreliable channel을 통해 구현해야 함을 나타낸다. |
reliable channel이란?
no error,no lost,in-order. 즉, 데이터가 손상 없이, 손실 없이, 순서대로 전송이 보장되는 데이터 이동 통로이다.
왜 실제 네트워크는 신뢰적이지 않은가? TCP/IP 아키텍쳐에 의하면, transport layer는 network layer 위에서 수행된다. 이 network layer는 신뢰성을 보장하지 않는다. 따라서 이전에 봤었던 host-to-host logical communication 자체가 신뢰적이지 못하니, process-to-process logical communication 또한 기본적으로 신뢰적이지 못한 것이다.
그럼 우린 어떻게 이 신뢰적이지 못한 채널 위에 신뢰성 있는 데이터 전송을 이룰 수 있을까? 처음엔 신뢰성에 관한 모든 것을 보장해주는 모델부터 점점 보장해주는 것이 적어지는 모델들을 차례차례 살펴볼 예정이다. 여기서 보장되는 것이 점점 없어졌을 때, 신뢰성 있는 전송을 보장해주기 위해 어떠한 구현들이 점점 추가되는지를 주의깊게 살펴보자.
RDT - Getting Started
이 RDT 구현들을 FSM(Finite State Machine)을 통해서 설명할 것이다.
FSM이란? 어떠한 상태에 있을 때 특정 이벤트가 발생하면 "Transition(전이)"이 발생하는 동작방식을 말한다. 전이가 발생하게 되면 다른 상태로 바뀌게 된다. 이해가 안가도 아래의 설명들을 보면 이해가 갈 것이라 생각한다.
위 그림에서의 일반적인 동작 순서 : rdt_send() ➡ udt_send() ➡ rdt_rcv() ➡ deliver_data()
rdt_send() : 응용프로그램에서 transport layer로 데이터를 내려보내는 동작을 나타낸다.udt_send() : "unreliable channel"을 통해 sender에서 receiver로 데이터를 전송하는 동작을 나타낸다.rdt_rcv() : "unreliable channel"을 통해 receiver가 sender로부터 데이터를 전송받았음을 나타낸다.deliver_data() : receiver가 받은 데이터를 위 응용프로그램으로 올려보내는 동작을 나타낸다.FSM의 전이 : 분모는 Action, 분자는 event를 적는 방식으로 전이를 표현할 것이다.
RDT - rdt1.0 : over a reliable channel
rdt1.0 버전은 channel이 reliable하다고 생각하고 전송한다.
RDT - rdt1.0 : FSM
| (a) rdt1.0: 송신 측 | (b) rdt1.0: 수신 측 |
|---|---|
|
|
여기선 볼 것이 없으니, 바로 rdt2.0으로 넘어가보자.
RDT - rdt2.0 : over a channel with bit errors
rdt2.0➡checksum&&ACK / NAK
보장하지 않게 된 것 : "unreliable channel"로 인해 비트 에러가 발생할 수 있게 되었다. 이에 따라 error detection과 error recovery 의 기능이 추가되어야 한다.
사람과의 대화로 비유
| 사람 | 컴퓨터 |
|---|---|
| 대화를 하면서, ok 또는 not ok를 통해 다시 말할 것을 요청하여 정확히 대화가 오고가도록 한다. | ARQ(Automatic Repeat reQuest) 프로토콜을 구현함으로써 재전송 메커니즘을 통해 RDT를 수행한다. |
ARQ란?
Automatic Repeat reQuest의 약자로, 데이터 통신에서 오류 제어 방법 중 하나이다. 이 방법은 수신 측이 데이터 패킷을 받았을 때 그것이 정확한지 확인하고, 오류가 있으면 송신 측에 재전송을 요청하는 방식을 사용한다.
이 ARQ로 비트 에러를 처리하기 위해선 3가지 매커니즘이 더 필요하다.
RDT - rdt2.0 : ARQ를 위한 3가지 매커니즘
1. Error detection
- 수신 측 입장에서 비트 에러가 발생했을 경우 이를 감지할 수 있어야 한다.
- 여러 detection(감지)과 correction(정정) 기법들이 있지만, 여기선 이를 위해
추가 비트들이 필요하다는 것만 알아두자. - 이 추가 비트들은
checksum을 위한 비트가 될 것이다.
2. Receiver feedback
ACK(Acknowledgment)와NAK(Negative Acknowledgement)을 알려주는 패킷이 필요하다. ACK는 송신자가 보낸 패킷에 대해 잘 받았다는 뜻이고 NAK는 잘 받지 못했다는 뜻이다. 이를 패킷에 담아 송신자 측에 전달해야 한다.- 1비트 면 충분하다. ➡
NAK : 0,ACK : 1
3. Retransmission
- 수신자 측에서 에러를 감지하면, 이를 알린 후 송신자 측에서 다시 패킷을 보내는 과정이 추가되어야 한다.
RDT - rdt2.0 : FSM
| rdt2.0: 송진자 측 | rdt2.0: 수신자 측 |
|---|---|
 |
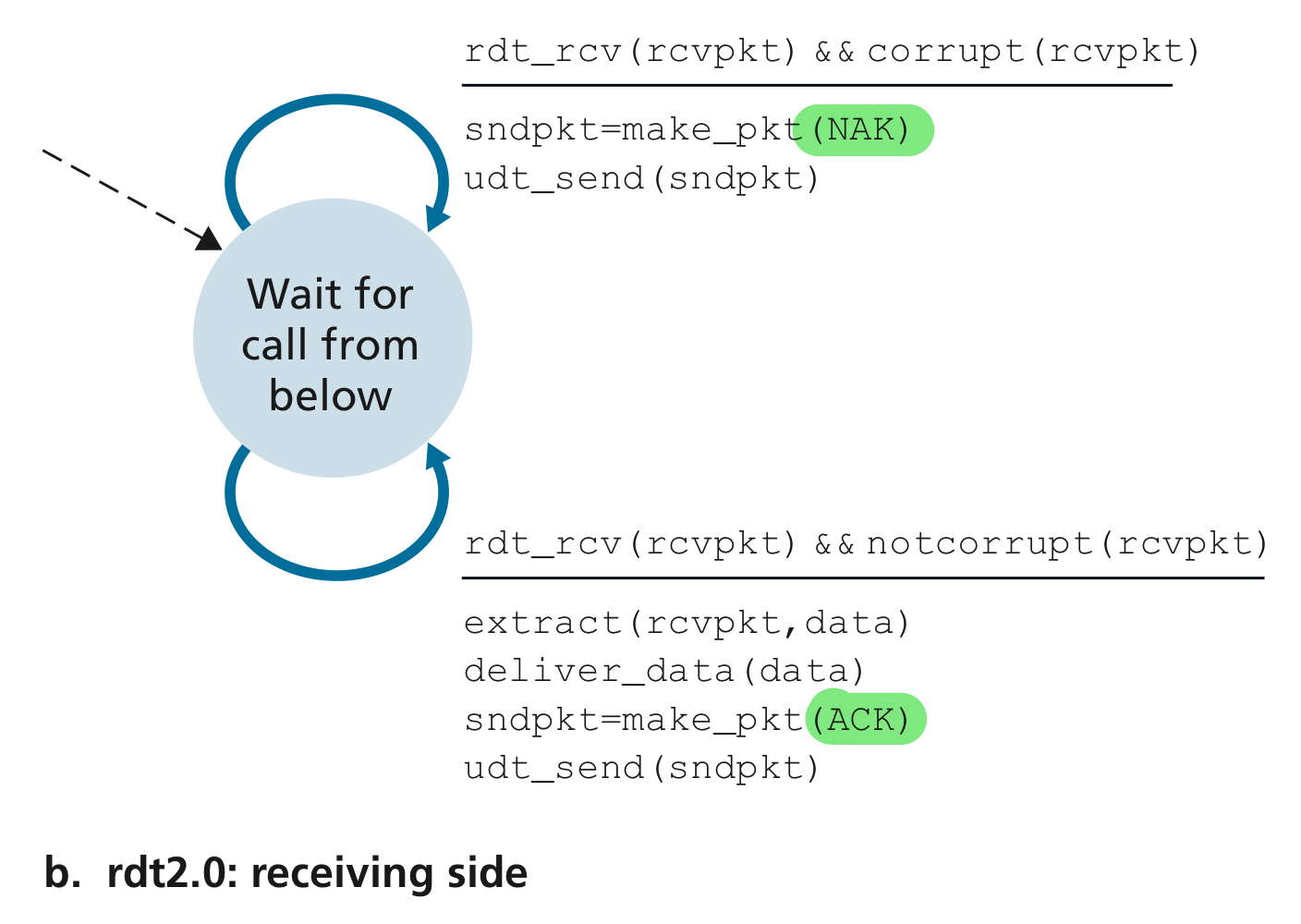 |
sender의 FSM의 바뀐 점
- checksum을 포함하는 패킷을 만듦
- 수신자 측으로부터 ACK와 NAK 패킷을 기다린다.
- ACK 패킷을 받은 경우에만 다음 패킷을 보낼 준비를 한다.
receiver의 FSM의 바뀐 점
- 보낸 패킷에 에러가 있는지 확인하는 동작이 추가되었다.
- 에러가 있을 때는 NAK, 없을 때는 ACK 패킷을 만드는 동작이 추가되었다.
- 에러가 없을 때만 위로
deliver_data()를 수행하게 되었다.
주목할 점
송신자 측은 수신자 측으로부터 ACK를 받지 못하면, 위 응용프로그램이 보낼 데이터 또한 받지 못한다. 즉, 한번 보낸게 완벽히 보내져야만 다음 패킷을 준비해서 보낼 수 있게 된다. 이러한 매커니즘을 stop and wait protocol이라고 한다.
RDT - rdt2.0 : Fatal Flow!
ACK와 NAK전송 또한 데이터 전송이다. 즉, 이 ACK/NAK 또한 corrupt 될 수 있다는 뜻이다. 그럼 ACK와 NAK 패킷이 corrupt될 때는 어떻게 해결할 수 있는지도 알아야 한다. 아래 3가지 후보들을 봐보자.
- 송신자는 다시 ACK / NAK을 보내달라는 패킷을 보낸다. ➡ 이는 혼란을 야기한다. 이 메시지가 다시 보내달라는 메시지인지, 아니면 새로운 메시지인지 알 수 있는 방법이 없다.
- 충분한 checksum bit들을 추가한다. ➡ 이건 corrupt packet, 즉 에러가 발생한 패킷을 처리할 수는 있겠지만 loss(손실)에 대해서는 처리할 수 없다.
Garbled ACK / NAK을 받은 송신자는 다시 데이터를 전송한다. ➡ 이는 중복 패킷 문제를 야기한다. 즉 수신자가 이 패킷이 중복된 것인지 새로운 패킷인지를 알 방법이 없다.
Garbled ACK / NAK : 에러가 발생한 ACK / NACK을 말한다.
RDT - rdt2.1 : for garbled ACK / NAK
rdt2.1➡checksum&&ACK / NAK&&sequence number
위에서 rdt2.0의 fatal flow를 해결하기 위해 sequence number라는 것을 도입한 rdt2.1을 알아보자.
보장하지 않게 된 것 : rdt2.0에서 도입한 ACK / NAK 패킷 또한 에러가 발생할 수 있게 되었다.
sender의 변경점
- 보내려는 패킷에 시퀀스 넘버 필드를 추가해서 이와 같이 보낸다.
- 이 시퀀스 넘버는 패킷의 신원을 확인하는 ID 역할을 하게 될 것이다.
receiver의 변경점
- receiver는 받은 패킷의 시퀀스 넘버를 확인하는 로직만 추가하면 된다.
이와 같은 변경점을 통해 receiver는 같은 시퀀스 넘버를 가지는 패킷을 받았다면 '이 패킷은 재전송된 패킷이구나', 'ACK / NAK에 에러가 생겨 sender가 잘 알아듣지 못했구나' 라고 인지하여, 다시 ACK / NAK 패킷을 보낸다.
sequence number를 위한 bit 크기는?
- 1bit면 충분하다.
- 현재 rdt2.1에선 stop-and-wait 프로토콜을 보고 있다. 이에 따라, 0과 1로 중복된 것인지 아닌지를 확인할 수 있는 것이다.
왜 stop-and-wait 프로토콜을 사용하면 시퀀스 넘버는 1비트로 충분한가? stop-and-wait 프로토콜은 하나의 패킷이 정확히 처리되어야만 다음 패킷을 처리하는 방식이다. 즉 sender와 receiver는 한번에 하나의 패킷만을 처리할 수 있다. 이 때 중복된 패킷을 구분하기 위해선 직전과 현재, 또는 현재와 직후의 패킷을 구분할 수 있어야 하는데, 한번에 하나의 패킷만을 처리하기 때문에 0과 1을 통해 현재의 것과 직전 또는 직후의 패킷을 구분할 수 있다. 만약 여러 패킷이 동시에 전달될 수 있는 상황(sliding window 프로토콜의 경우)이라면, 시퀀스 넘버는 더욱 많이 필요하게 될 것이다.
RDT - rdt2.1 : FSM
| rdt2.1: sender | rdt2.1: receiver |
|---|---|
 |
 |
주목할 점
- rdt2.0보다 state가 2배로 많다. 시퀀스 넘버가 0 또는 1임을 기억해야 하므로 이에 대한 state가 생겨났기 때문이다.
- receiver는 시퀀스 넘버가 0인지 1인지를 확인한 후 중복된 패킷인지를 알아내야 한다.
RDT - rdt2.2 : NAK-free protocol
rdt2.2➡checksum&&ACK&&sequence number
보장하지 않게 된 것 : rdt2.1과 동일하다.
rdt2.2의 발단
- 프로토콜은 간단하면 간단할수록 좋다.
- ACK에 시퀀스 넘버를 추가함으로써 가능하다.
- 만약 sender가 이전과 동일한 시퀀스 넘버의 ACK 패킷을 받았다면, 이는 receiver 쪽에서 현재 NAK 패킷을 보냈다고 이해를 하면 된다.
- 예) sender가
ACK 0를 받았음에도 이후에 또ACK 0을 받았다면, sender는 0번 패킷에 대해 재전송을 수행한다.
RDT - rdt2.2 : FSM
| rdt2.2: sender | rdt2.2: receiver |
|---|---|
 |
 |
주목할 점
- receiver의 ACK에도 시퀀스 넘버가 붙게 되었다. 이 시퀀스 넘버를 통해 sender는 중복된 ACK를 받았는지 아닌지를 알 수 있게 되었다.
- 이를 위해 sender측에 ACK 패킷의 시퀀스 넘버를 확인하는 로직이 추가되었다.
💡 **지금까지의 과정
- checksum을 통한 error detection (rdt1.0)
- ACK / NAK packet을 통해 error를 알림 (rdt2.0)
- sender의 retransmission으로 error를 recover (rdt2.0)
- ACK / NAK packet에서도 마찬가지로 일어날 수 있는 error에 대해, sequence number를 통해 sender의 packet이 retransmission인지 new packet인지를 receiver가 구분 가능 (rdt2.1)
- 이후 더 가볍게 하기 위해, ACK + sequence number를 통해 NAK을 대체 (rdt2.2)
하지만 이 과정들에서 에러는 해결할 수 있었지만, 손실(loss)에 대해선 처리할 수 없없다. 이에 손실이 발생했을 때에도 RDT를 구현할 수 있는 방법을 알아보자.
RDT - rdt3.0 : Channels with Errors and Loss
rdt3.0➡checksum&&ACK&&sequence number&&timer
보장하지 않게 된 것 : 패킷 손실이 발생할 수 있게 되었다. 따라서 패킷 손실에 대한 매커니즘이 필요해졌다.
loss 관련 이슈
- loss detection
- loss recovering
이 두개에 대한 책임을 sender에게 부여해보자!
loss detection
- sender가 타이머를 통해 특정 시간동안 ACK가 오지 않으면
timeout을 발생시킨다.
loss recovering
- timeout이 발생하면 sender는 재전송을 수행한다.
- 송신자 측에서 보내는 패킷이 손실되어 ACK가 안오는 것이던, ACK가 손실되어 안오는 것이던간에, 모든 경우에 대해 sender는 재전송을 수행한다.
- 그럼 receiver가 중복된 패킷을 받을 수도 있지 않나? 이는 rdt2.2버전까지의 구현으로 충분히 처리 가능한 문제이다.
그럼 timeout 시간은 어떤 값으로 설정하는가? 이 내용은 3.5장에서 TCP의 구현을 살펴보면서 자세히 다룰 것이다. 현재는 단순히 "적당한 시간"이라고 생각하고 넘어가자.
RDT - rdt3.0 : FSM
| rdt3.0: sender |
|---|
 |
주목할 점
- receiver는 달라진 점이 없다. 모든 손실에 대한 책임을 sender가 지게 했기 때문이다.
- sender의 경우
countdown 타이머가 생겨났다. - 이 타이머에 대한
timer start로직이 생겨났다. timeout에 대한 인터럽트에 반응하는 로직이 생겨났다.timer stop로직이 생겨났다.
RDT - rdt3.0 : 가능한 case들
| (1) 손실이 없는 경우 | (2) 패킷 손실이 있는 경우 |
|---|---|
 |
 |
| (3) ACK 패킷 손실이 있는 경우 | (4) premature timeout 또는 ACK패킷의 지연이 있는 경우 |
|---|---|
 |
 |
※ (4) premature timeout 또는 ACK패킷의 지연이 있는 경우
timeout이 지연된 시간보다 빨리 발생했을 때는 문제가 없다. 왜 없는지를 간단하게 살펴보면,
- sender 입장에선 timeout이 되었으므로 재전송을 수행한다. 이는 receiver 입장에선 중복된 패킷으로 인지하게 된다. receiver는 sender에게
ACK 1패킷을 다시 전송해준다. ➡ 문제가 없다! - sender는 다시 재전송한 이후 지연된
ACK 1을 받는다. (이 ACK 1 패킷은 1번에서 receiver가 ACK 1을 보내기 전에 보낸 패킷이다)
➡ sender 입장에선 재전송 한 것에 대해 receiver가 ACK 1을 보낸 것이라고 판단한다.
➡ 따라서 다음 패킷인 0번 패킷을 보낸다.
➡ 보내고 난 후, 위 1번 과정에서 receiver가 다시 재전송해준 ACK 1을 또 받는다.
➡ sender 입장에선 ACK 1을 받으면 0번 패킷을, ACK 0을 받으면 1번 패킷을 보내는 매커니즘대로, ACK 1을 또 받았다는 것과는 별개로 어쨌든 받았으니 0번 패킷을 보낸다.
💡 시퀀스 넘버가 0과 1이 번갈아가는 방식을
Alternating bit protocol이라고 한다.
요약
- RDT1.0 버전은 데이터 이동 채널 자체가 신뢰성이 있다고 가정한다. 따라서 아무 문제가 없었다.
- RDT2.0 버전은 비트 에러가 있다는 것을 가정한다. 이에 따라 에러 감지 및 에러 복구 매커니즘이 필요했다. 에러 감지는 checksum을 통해 수행할 수 있었고, 에러 복구는 재전송을 통해 이뤄졌었다. sender가 재전송을 수행할 수 있도록 receiver측에서 ACK 또는 NAK 패킷을 보냈었다.
- RDT2.1 버전은 위 ACK / NAK 패킷 또한 에러가 날 수 있는 패킷(garbled ACK / NAK)임을 상기했다. 이에 sender가 ACK / NAK 패킷이 에러가 났을 경우에도 재전송을 수행하도록 했다. 이렇게 receiver가 제대로 받지 못한 경우와 sender가 제대로 받지 못한 경우, 이렇게 두가지 경우 모두 sender가 재전송을 수행하도록 하였더니, receiver 입장에서는 sender의 재전송으로 인한 중복된 패킷을 받는 것인지 아니면 새로운 패킷을 받는 것인지 알 수 없게 되었다. 이에 시퀀스 넘버를 추가하여 직전 패킷과 같은 패킷인지, 아니면 새로운 패킷인지를 알 수 있게 되었다.
- RDT2.2 버전은 위의 ACK / NAK를 단순화 하여, ACK 0이면 NAK을, ACK 1이면 ACK를 나타내도록 하였다.
- RDT3.0 버전은 패킷 손실이 있다는 것을 가정한다. 이를 위해 타이머를 두어 receiver로부터 응답이 일정 시간 오지 않을 경우, timeout을 발생시켜 재전송을 수행하도록 했다.
더 알아보기
출처
Computer Networking: a Top Down Approach 中 3.4장


